时隔3年后,国际多通道语音分离和识别评测CHiME-7再次“上线”。继2016年以来参与CHiME-4、5、6三届评测并夺冠后,中科大语音及语言信息处理国家工程研究中心(NERC-SLIP)杜俊副教授带领团队联合科大讯飞研究院(以下简称“USTC-NERCSLIP联合团队”),投入了长达5个月的时间和精力,尝试各种不同的方法和策略,以应对复杂的语音信号处理和语音识别的挑战,最终在参与的多设备多场景远场语音识别任务(DASR)中获得全部两个赛道的第一。

USTC-NERCSLIP联合团队人员
语音识别任务难度加码!“群雄逐鹿”再领头
作为有“最难语音识别任务”之称的语音领域权威评测,CHiME(Computational Hearing in Multisource Environments)系列评测发起于2011年,致力于集聚学术界和工业界优秀的学术力量,持续突破语音识别技术水平,不断在更高噪声、更高混响、更高对话复杂度的场景下提出具有创新性的解决方案,解决著名的“鸡尾酒会问题”——难点在于怎样在充满噪声的鸡尾酒会,分辨并听清多人同时交谈的声音。
参与CHiME-7的团队高手如云,如日本电信公司NTT(CHiME-1和CHiME-3冠军)、俄罗斯STC(CHiME-6 Track 2冠军)、英伟达、剑桥大学、帕德博恩大学、捷克布尔诺理工大学BUT(国际说话人日志评测DIHARD-I和DIHARD-II冠军)、中科院声学所、西北工业大学等国内外知名研究机构、高校和企业。本次CHiME-7中的语音识别任务由卡内基梅隆大学、约翰霍普金斯大学、东京都立大学和马尔凯理工大学的学者们共同组织,称为“多设备多场景远场语音识别任务(DASR)”。
在CHiME-6的基础上,CHiME-7进一步提升了难度,不仅在对话场景、麦克风设备类型上进行了扩充,同时要求参测者只能使用统一的一套算法系统进行测试,这对语音识别系统的鲁棒性提出了极高的要求。具体如下:
Ø在考察场景中,扩大了CHiME-6测试集范围,同时新增加了两个数据集DiPCo和Mixer 6;
Ø三个数据集分别使用不同的麦克风设备,包含线性阵列、环形阵列、分布式麦克风等;
Ø数据集中多人对话空间场景更加丰富,除朋友聚会之外还新增了采访、打电话等场景。
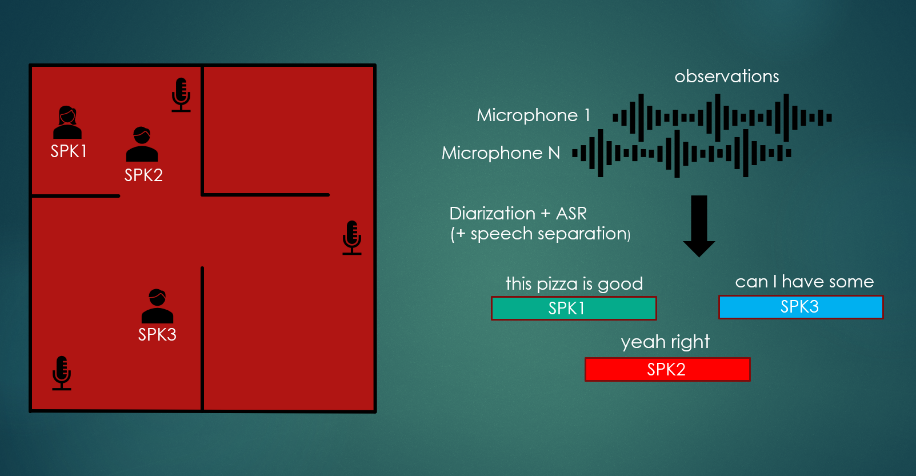
CHiME-7官方给出的任务图例
该任务分为主赛道(Main Track,默认提交)和子赛道(Sub Track,自由提交),具有很高的挑战性,也与真实复杂场景中的语音识别要求更为贴近:
Ø主赛道需要首先要完成远场数据下的说话人角色分离任务,即从连续的多人说话语音中切分出不同说话人片段、判断出每个片段是哪个说话人,然后再进行语音识别;
Ø子赛道中说话人角色分离的信息是人工标注的,参测者可以直接使用,在人工分离边界的基础上直接进行语音识别。
此次评测核心考察指标为DA-WER(Diarization Attributed WER),即综合考察系统对多个说话人的角色分离效果,以及语音识别效果。
USTC-NERCSLIP联合团队参加了所有两个赛道,在主赛道和子赛道分别以21%和16%语音识别错误率拿下双冠,将真实说话人角色分离情况下的语音识别错误率与使用人工标注间的差别控制在5%,这也标志着在实际环境中的应用效果将得到进一步提升。
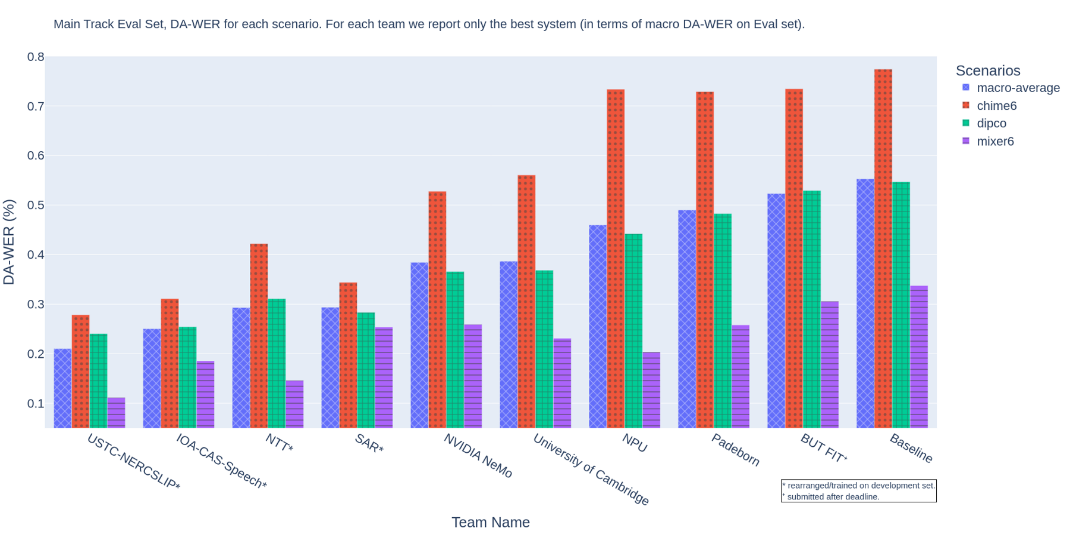
主赛道语音识别成绩,排名指标DA-WER取自三个数据集上的平均值,值越低成绩越好
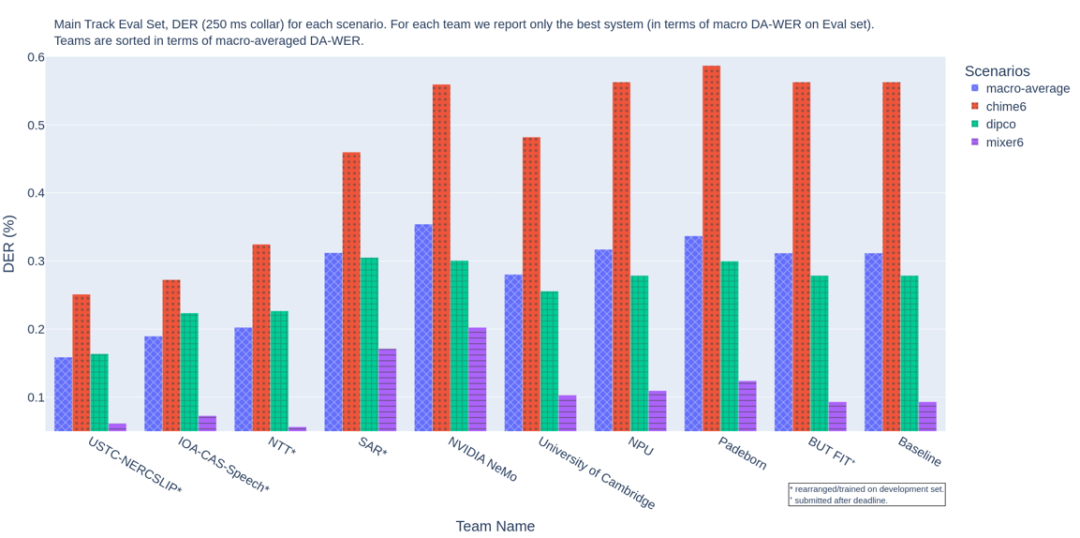
主赛道说话人角色分离成绩,排名指标DER代表说话人角色分离错误率,值越低成绩越好
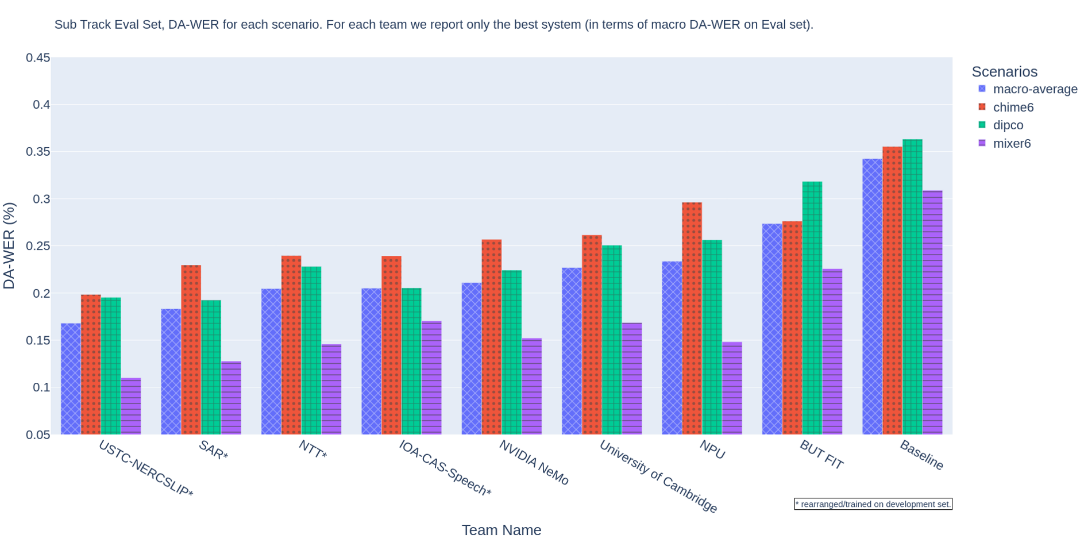
子赛道语音识别成绩,排名指标DA-WER取自三个数据集上的平均值,值越低成绩越好
面对挑战,我们的“新招数”有哪些?
如何突破语音交叠、远场混响与噪声干扰、随意的对话风格等重重难关,在更复杂的语音素材里精准实现说话人角色分离和语音识别?
基于长期技术积累,USTC-NERCSLIP联合团队创新并使用了多种技术方法。
Ø基于记忆模块的多说话人特征神经网络说话人角色分离算法 (Neural Speaker Diarization Using Memory-Aware Multi-Speaker Embedding , NSD-MA-MSE)
该方法旨在解决高噪声、高混响、高说话人重叠段场景的说话人角色分离问题。基于对大规模的说话人聚类得到的类中心向量,团队设计了一种记忆模块,可以利用该模块与当前目标人片段,通过注意力机制计算来得到更加精确的目标说话人特征。整体上,团队采用序列到序列的方式来预测多个说话人的输出帧级语音/非语音概率。该模型极大降低了说话人角色分离错误率,有效地帮助了后续的分离和识别模块。
Ø阵列鲁棒的通道挑选算法(Array-Robust Channel Selection)
该算法基于波束语音信噪比挑选准则,即使对于不同的阵列分布场景,也能够自动挑选出有效通道,从而减少下游任务无效噪声和语音干扰。同时,团队提出了一种空间-说话人同步感知的迭代说话人角色分离算法(Spatial-and-Speaker-Aware Iterative Diariazation Algorithm,SSA-IDA),通过结合阵列空间建模和机器学习长时建模的优势,迭代修正说话人角色分离系统中声学特性相似的说话人错分情况,从而更加精确捕捉目标说话人的信息。
该算法不仅有效的降低了环境干扰噪声,而且可以进一步消除干扰说话人的语音,从而大幅降低下游语音识别任务的难度。
Ø场景自适应自监督表征学习方案(Scene Adaptive Self-Supervised Learning Method)
该方案用于匹配复杂场景的语音识别,将经过前端处理后的音频作为自监督模型的输入,并提取高层次表征作为指导标签,实现了对特定场景的快速自适应匹配;同时,结合层级渐进式学习和一致性正则约束,进一步提高了预训练模型对下游语音识别任务的鲁棒性。利用预训练模型的层级信息进行融合,实现了语音识别在复杂场景的效果提升。
更多详细内容参考:
评测官方网站:https://www.chimechallenge.org/current/task1/index
官方总结:www.chimechallenge.org/current/workshop/papers/CHiME_2023_DASR_cornell.pdf
USTC-NERCSLIP联合团队技术报告:
www.chimechallenge.org/current/workshop/papers/CHiME_2023_DASR_wang.pdf
(电子工程与信息科学系)




